
Spatial Index - An Efficient way to find objects nearby
This weekend I found myself thinking, "I want to have 1000 objects on screen interacting efficiently online."
Don't ask me why! Not even I know the answer to that, but I thought this would be a good first step. And I wanted this to be done in an efficient way. Here, I'll share the challenges of this premise through an interactive visualization that you can play with in your browser too.
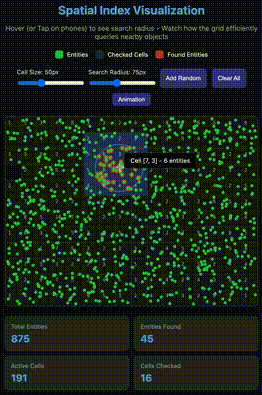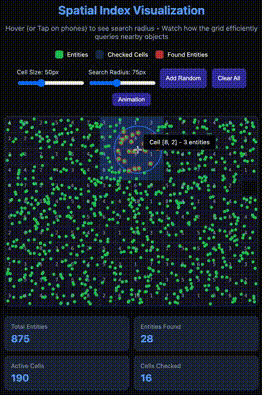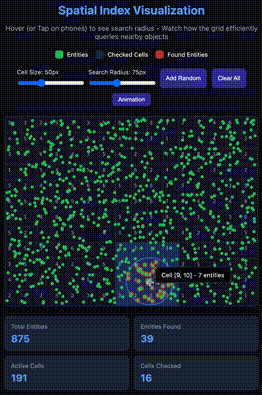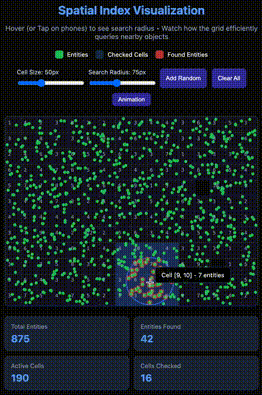
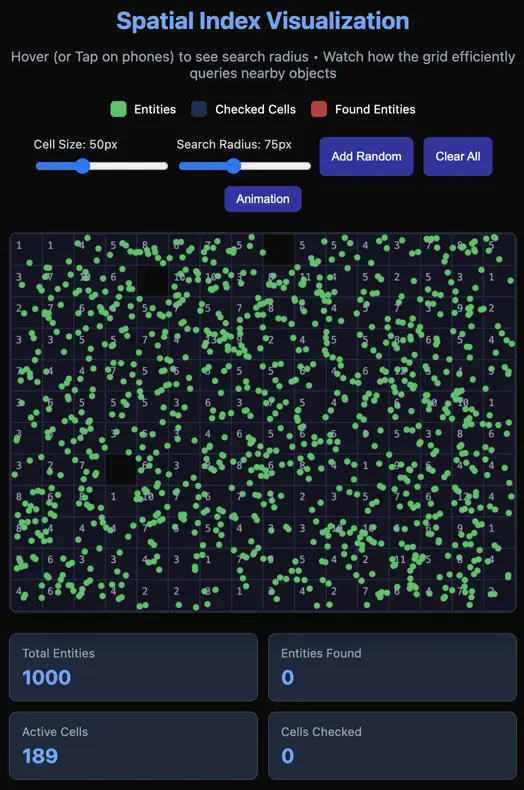
As you can see in the GIF above, there's a circular area where objects change color from green to red. These are marked using the Spatial Index technique, which is also part of many well-known solutions such as spatial databases, map/location applications (e.g., Uber, Google Maps), and Game Engines.
Why is this technique necessary?
Let's first see how we could handle this in a naive and inefficient way.
Let's say we have the following:
- A
mapof size 10×10cells(or tiles, or whatever measurement you want to use to divide an area into subareas) with 100 coordinates (1 per cell) - 100
entities(these could be restaurants, taxis, players, NPCs, etc.) - A
radiusand acenter coordinate(this could be a person wanting to buy food, find a nearby taxi, a player being affected by some AOE skill, etc.)
The naive implementation would simply compare every entity in the map and see if the distance to the center coordinate is less than or equal to the radius:
List<Object> entities = ...
int radius = 1;
Object centerObject = new Object(coordinateX, coordinateY);
for(Object object : entities) {
if(object.isCloseTo(centerObject, radius)) {
//found... add to a list
//and eventually return the list of nearby objects
}
}
So what's the problem here? Let's say you are a worldwide company that has hundreds of thousands or even millions of objects of interest. We'll have to do an O(n) search here for each request.
You might say, What if we simply use a database and filter by region/country/city?
That doesn't work with live data like moving objects, because you would have to insert into the database every few seconds to update the map applications (restaurant deliveries, taxi applications, etc.). It simply doesn't scale.
The same applies to games, and let me tell you that here it's even worse given the nature of some genres and the high density of interacting objects in a small area, but I'll get back to that later.
How does Spatial Indexing solve this?
By simply dividing the grid into multiple cells, and instead of having a global list of entities, we have one for each cell. This way, the problem is divided efficiently and searches in an evenly distributed map would be much more efficient.
function findNearby(centerX, centerY, radius) {
const found = [];
const checkedCells = new Set();
...
for (let cellX = minCellX; cellX <= maxCellX; cellX++) {
for (let cellY = minCellY; cellY <= maxCellY; cellY++) {
const key = `${cellX},${cellY}`;
checkedCells.add(key);
const cellEntities = spatialGrid.get(key) || [];
cellEntities.forEach(entity => {
const dx = entity.x - centerX;
const dy = entity.y - centerY;
const distSq = dx * dx + dy * dy;
if (distSq <= radius * radius) {
found.push(entity);
}
});
}
}
return { found, checkedCells };
}
This way, we don't have to iterate over all entities in the map, but only a subset of cells that can be reached by the radius only. This means the whole map could be huge, theoretically infinite.
However a keyword here is "evenly distributed," because otherwise you would end up with the same initial problem of having to iterate through all the entities.
Now, this is just one implementation of spatial indexes, which is grid-based. There are others, such as QuadTrees and many more, which are better at handling static data. In my case, I'm interested in live and moving data with a simple implementation adaptable for new ideas.
The Online Challenge
There's a big problem with my initial premise of trying to have 1000 objects on screen interacting efficiently. I wanted this to be feasible online, so that each of those objects/entities could be a person connecting and seeing 999 others on the same screen.
You can see this in the browser yourself —just add enough entities until you reach ~1000.
And here's the major flaw when we speak about online and networking:
The server needs to send updates to ALL clients every tick, effectively making this a O(n2) problem:
- For 2 objects in an area, you have to send 2 clients 2 object updates (4 updates)
- For 10 objects in an area, you have to send 10 clients 10 object updates (100 updates)
- For 100 objects in an area, you have to send 100 clients 100 object updates (10k updates)
- For 1000 objects in an area, you have to send 1000 clients 1000 object updates (1M updates)
Plus every tick is usually in terms of fractions of seconds (20ms, 100ms, etc.), meaning you have to do this multiple times per second for a fluid or smooth experience.
Not scalable at all.
After doing some performance testing and tweaking the server-side code to make it more efficient, I realized that there's a lot that needs to be done to allow 1000 objects to interact efficiently on the same screen while being online:
- Send only changed data. For example, if a player doesn't move, we shouldn't send updates about that particular object to everyone in the area.
- Parallelize everything you can to make use of all CPU cores on the server.
- Allow clients to process some data, and use the server only to verify relevant events (e.g., when an order is actually confirmed, when a player tries to attack another player, etc.). This way we offload some processing to the clients.
- Slow down updates sacrificing smoothness when there's too many objects interacting nearby.
- Think outside the box. What if we don't care about the hundreds of interactions, but only about some of them?
That last item is food for thought, and those kinds of limitations might give you some hints toward a creative way to handle this. This would allow every person behind a mobile phone or computer playing the game to see what's happening, but the server would only need to manage a subset of the interactions. I won't go beyond this thought and will leave it here because I'm still trying to figure out the answer, but it seems like a fun challenge to have.